
Dissonance Twitter Dataset
Published:
Within-person cognitive dissonance dataset collected from annotating tweets for within-person dissonance, as described in our paper Transfer and Active Learning for Dissonance Detection: Addressing the Rare Class Challenge. The data repository is here.
Annotation details
Tweets were parsed into discourse units, and marked as Belief (Thought or Action) or Other, and pairs of beliefs within the same tweet were relayed to annotators for Dissonance annotation.

The annotations were conducted on a sheet in the following dissonance-first format.

The annotators used the following flowchart as a more detailed guide to determining the Dissonance, Consonance and Neither/Other classes:
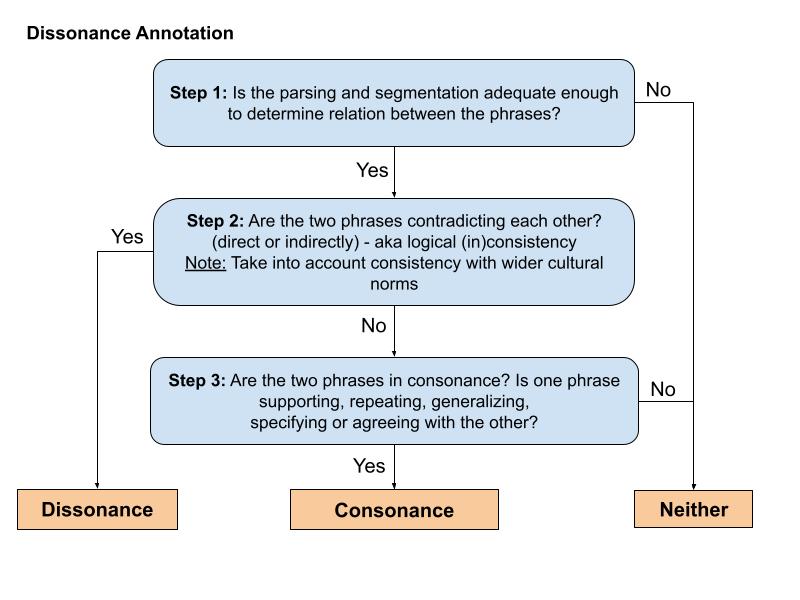
Data Organization
In the folder ./data/, you can find the following files containing the data:
train_small.json: Small train set as described in Section 4.4 of the paper, containing 2924 examples (6.29% dissonance)train_big.json: Big train set as described in Section 4.4 of the paper, containing 6649 examples (10.40% dissonance)dev.json: The final development set as described in Section 3.1, containing 1484 examples (10.24% dissonance)test.json: The final test set as described in Section 3.1, containing 1456 examples (10.30% dissonance)
Data Format
- Each example has a unique
id. - The
messagecontains the entire message so that it provides the context of the Belief units. - The two belief discourse units are recorded for each message in the fields
du1anddu2respectively. - The discourse units in a
messageare marked using angled brackets “<” and “>”. - Each example is classified with a
labelof “C” (Consonance), “D” (Dissonance) and “N” (Neither/Other).
Reading the data
If you would like to use the data in a dictionary by directly reading from the json files:
import json
train_dataset = json.load("data/train_big.json")
If you prefer dataframes, pandas should be installed in order to load the dataset. pip install pandas
Load the dataset using the following code snippet:
import json
import pandas as pd
with open('data/train_big.json', 'r') as f:
train_dataset = json.load(f)
df = pd.DataFrame(data)
Citation
If you use this dataset, please cite the associated paper:
@inproceedings{varadarajan2023transfer,
title={Transfer and Active Learning for Dissonance Detection: Addressing the Rare-Class Challenge},
author={Varadarajan, Vasudha and Juhng, Swanie and Mahwish, Syeda and Liu, Xiaoran and Luby, Jonah and Luhmann, Christian and Schwartz, H Andrew},
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Long Papers)",
month = july,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
abstract = "While transformer-based systems have enabled greater accuracies with fewer training examples, data acquisition obstacles still persist for rare-class tasks -- when the class label is very infrequent (e.g. < 5% of samples). Active learning has in general been proposed to alleviate such challenges, but choice of selection strategy, the criteria by which rare-class examples are chosen, has not been systematically evaluated. Further, transformers enable iterative transfer-learning approaches. We propose and investigate transfer- and active learning solutions to the rare class problem of dissonance detection through utilizing models trained on closely related tasks and the evaluation of acquisition strategies, including a proposed probability-of-rare-class (PRC) approach. We perform these experiments for a specific rare class problem: collecting language samples of cognitive dissonance from social media. We find that PRC is a simple and effective strategy to guide annotations and ultimately improve model accuracy while transfer-learning in a specific order can improve the cold-start performance of the learner but does not benefit iterations of active learning.",
}